Intelligent Controls
Return to all Research Topics
Reinforcement Learning in Control Systems
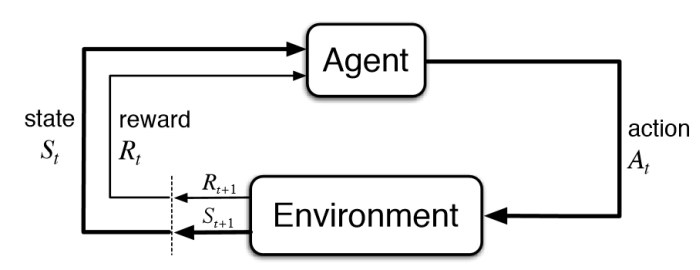 Reinforcement Learning (RL) is a subsection of Machine Learning which comes under the umbrella of unsupervised learning. Here an 'agent' takes an 'action' on an environment based on the current state of the environment, as shown in the adjacent figure.
Reinforcement Learning (RL) is a subsection of Machine Learning which comes under the umbrella of unsupervised learning. Here an 'agent' takes an 'action' on an environment based on the current state of the environment, as shown in the adjacent figure.
What we would like to see is that the 'agent' is sufficiently trained so that it takes the best action for every state the environment might be in, 'best' in the sense that out of all the possible actions the agent can take, it chooses the one which provides it the maximum reward. The reward for the agent is assigned through a carefully defined objective function. Hence, due to the nature of the RL structure, many of the simple RL algorithms are modelled as Markov Decision Processes (MDP). The advantages of RL over analytical methods of finding the optimal 'action' becomes apparent when the exact mathematical model of MDP's are not known or become highly intractable to solve.
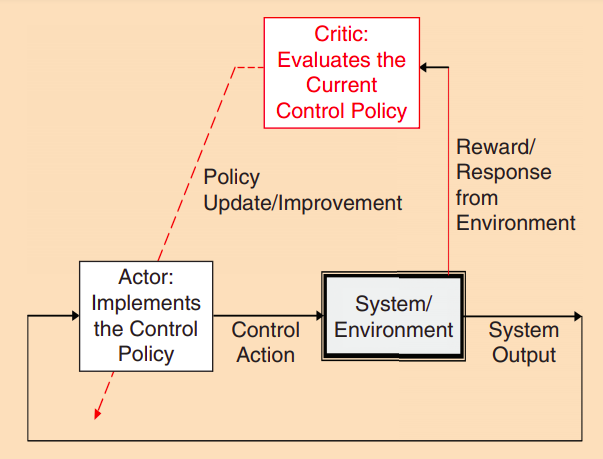 In the world of control systems we can define RL as a class of
methods that enable the design of adaptive controllers that learn online, in real time, the solutions to user-prescribed optimal control problems. So, the controller can be modelled as an 'agent' or an 'actor' while the plant (the system which we want to control) is the environment on which the controller takes action as shown in the adjacent figure.
In the world of control systems we can define RL as a class of
methods that enable the design of adaptive controllers that learn online, in real time, the solutions to user-prescribed optimal control problems. So, the controller can be modelled as an 'agent' or an 'actor' while the plant (the system which we want to control) is the environment on which the controller takes action as shown in the adjacent figure.
The application of RL in LIGO specifically is very wide due to the flexibility it provides. If proven better than the PID controllers, RL controllers can effectively replace PID controllers in various avenues requiring stability control in LIGO.
References:
- "Richard S Sutton and Andrew G. Barto, ``Reinforcement Learning: An Introduction,`` 2nd edition, The MIT Press 2018"
- "Introduction to RL"
- "F. L. Lewis, D. Vrabie and K. G. Vamvoudakis, "Reinforcement Learning and Feedback Control: Using Natural Decision Methods to Design Optimal Adaptive Controllers," in IEEE Control Systems Magazine, vol. 32, no. 6, pp. 76-105, Dec. 2012."